As I stated in the first part of this Continuous Integration series, one of the aims of storing your stuff under source control is being able to build your project from a fresh checkout, without needing to manually install or configure anything.
To accomplish this, it is always useful to use a standardized tree structure. You can have a look at some of the popular open source projects you use and love to get ideas on how to organize things. Now that your have everything under source control (don’t you?), we can start moving a few things around.
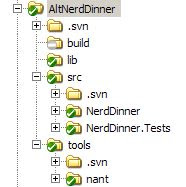 On the picture you can see a very typical structure for a project.
On the picture you can see a very typical structure for a project.
The src folder contains the different projects in their respective folders.
The lib folder will contain any third-party library needed to run our project. This is, any dependency that has to be deployed with our project (e.g. NHibernate, Windsor, etc).
The tools folders will contain any tools needed to build our project. It will contain tools like nant, nunit or fxcop, which we will use but won’t distribute with our application.
The build folder will hold the artifacts of the build.
Again, the purpose of putting all these libraries and frameworks under source control is to make EVERITHING needed to build and run your project available. Any new developer getting into your team should then be able to checkout your code and build it successfully, without needing to download and/or install anything from the Internet or hunt down any other dependencies your project builds upon.
If you need further info, I would recommend you to watch this screencast by Kyle "Dissociative identity disorder" Baley.